Sciences Po Paris
By: Carla Forster, Tomás Quintino Gouveia, Meire Klemmer, Aparna Rajesh, Naomi Schwarz
Executive summary
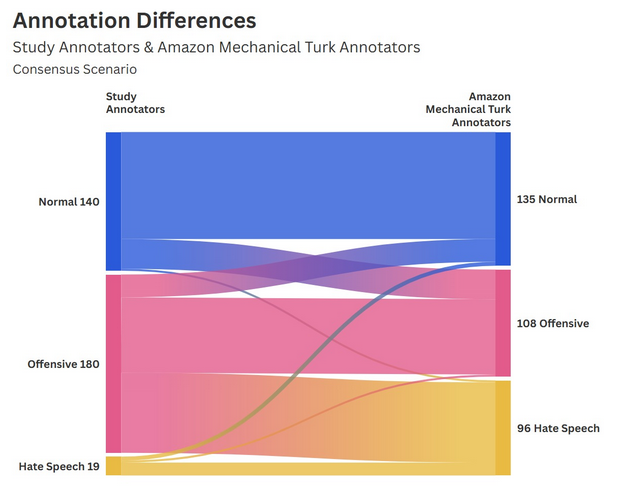
This project investigated the influence of dataset annotation on hate speech classification and the resulting implications for content moderation and platform governance. Our methodology centered on the HateXplain dataset, which contains over 20,000 posts from Twitter and Gab that were originally labelled by Amazon Mechanical Turk (AMT) workers, and from which we randomly selected a 500 post sample for our study. Each post was re-labeled by two human annotators (blind) to establish a human baseline, and then by two LLMs (Grok & Claude) to observe discrepancies.
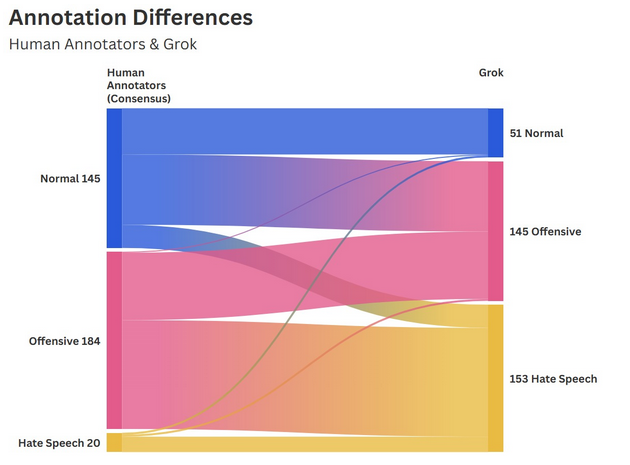
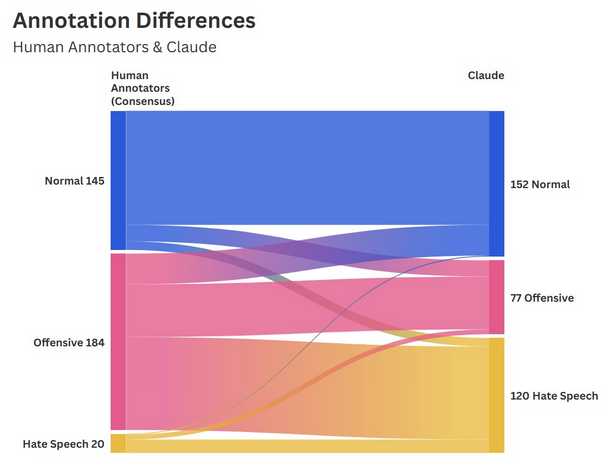
Our quantitative analysis revealed a moderate degree of agreement between human annotators, evidenced by a raw agreement average of 72.6%. Notably, the human consensus level was significantly higher for the “Normal” (75.1%) and “Offensive” (74.3%) label compared to “Hate Speech” (50.6%). Comparing the human labels to LLM tags, Grok displayed a far lower threshold for what was considered harmful content, labeling almost half of the sample (237 posts) as “Hate speech”, whereas the human consensus only found 20 cases. Claude’s labeling was more balanced but still resulted in an overlap of only 11.7% for “Hate speech”.
Qualitatively, the research identified that the LLMs generally lacked the social-situational awareness used by the human annotators to flag posts. Specifically, humans were at times able to identify cultural signifiers to infer identities and categorize the use of reclaimed slurs as humorous or self-depracating in-group slang and therefore “Normal”, while the LLMs categorically flagged trigger words as offensive or hateful. Furthermore, the models sometimes struggled with political discourse, flagging sensitive vocabulary such as “white people” or “feminists” as hate speech even when the content itself lacked clear incitement or an explicit attack.
Overall, the fundamental ambiguity surrounding the definition of an insult as opposed to hate speech is a significant barrier to effective classification. When the basis of a classification is built upon subjective and dynamic definitions, the resulting labels will inevitably reflect the personal and cultural biases of the annotators, while the AI model’s labels will fail to account for socio-cultural nuance. This points to significant doubts regarding labelled training datasets and who made them - what instructions were they given and which definitions were used? The bias that is introduced at the dataset level through humans is not to underestimate as it fundamentally changes how models - in this case BERT - classify things. In the given context of speech moderation, these understandings are ultimately the difference between removing unlawful speech and censorship of the public. This uncertainty suggests that content moderation is not only a technical problem to solve in ML algorithms necessitates social and cultural dialogue on how we define harm through speech.